Cela fait déjà quelque temps que GPT-4 fait la course en tête dans son domaine, loin devant les autres grands modèles de langage (LLM) qui alimentent la nouvelle génération de chatbots dopés à l’IA. Mais cela vient peut-être de changer. C’est en tout cas ce que revendique AnthropicAI avec Claude 3, la dernière itération de son modèle. Plusieurs benchmarks suggèrent qu’il dépasse désormais le bébé d’OpenAI, et qu’il dispose même de capacités « quasiment humaines » dans certains cas.
Ce nouveau modèle existe en trois versions : Haiku, Sonnet et Opus, la plus puissante. Cette dernière est présentée par Anthropic comme le « nouveau standard » de l’intelligence artificielle. Et il faut bien admettre que les résultats des benchmarks dévoilés par Anthropic dans son dernier billet de blog sont très impressionnants.
On constate en effet qu’Opus affiche des performances apparemment supérieures à celles de GPT-4 sur un large ensemble de tâches cognitives qui vont de la maîtrise du langage au raisonnement logique en passant par les mathématiques et la programmation.
GPT-4 battu sur de nombreux benchmarks courants
Par exemple, il a obtenu un score de 95 % sur GSM8K, soit trois points de plus que GPT-4 sur ce benchmark populaire qui teste les performances en mathématiques de niveau collège et lycée. La tendance est la même sur d’autres grands tests de maths appliquées. Claude est devenu le premier LLM à passer la barre des 60 % sur le benchmark MATH, alors que son rival n’atteint que 52,9 %.
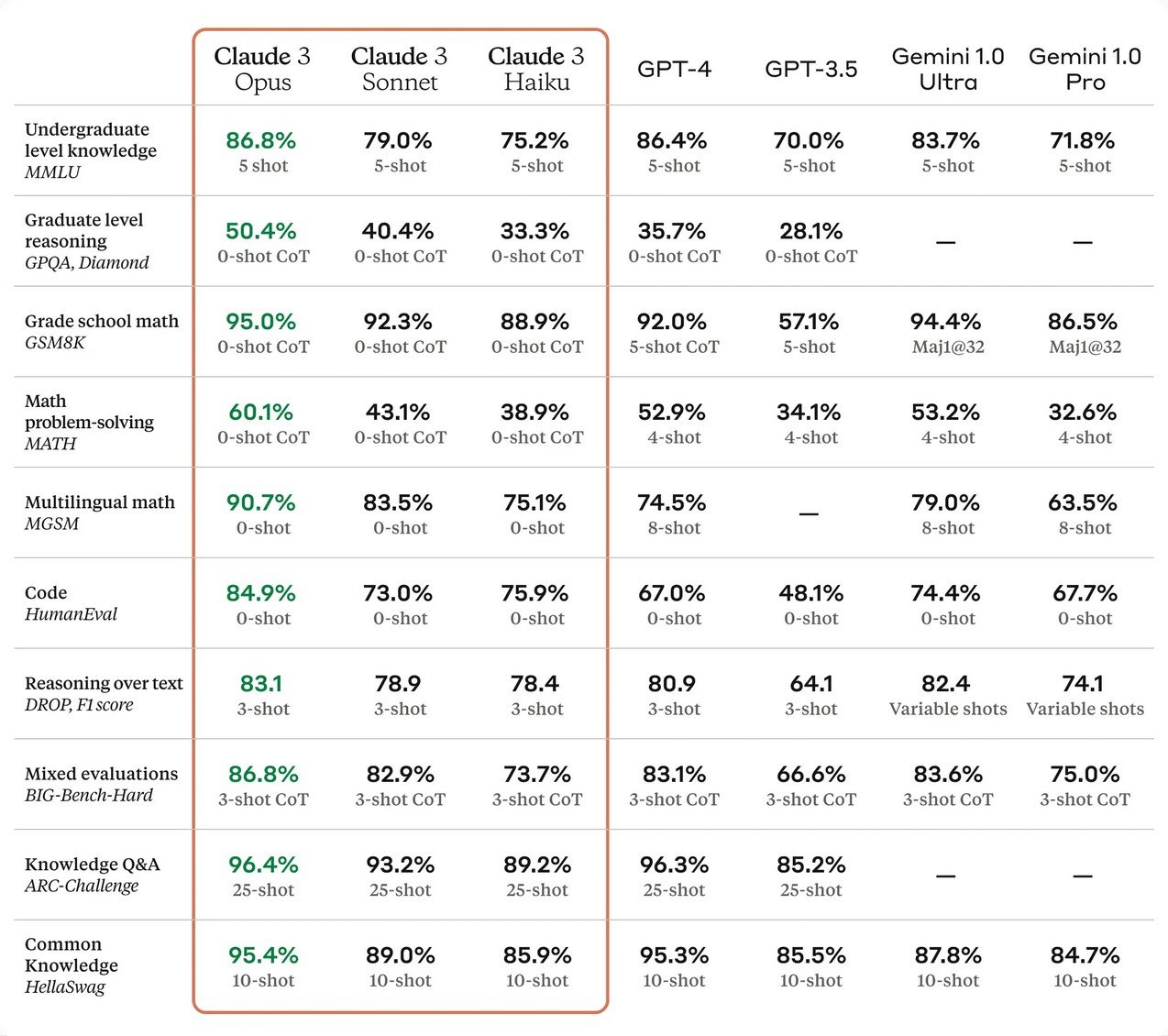
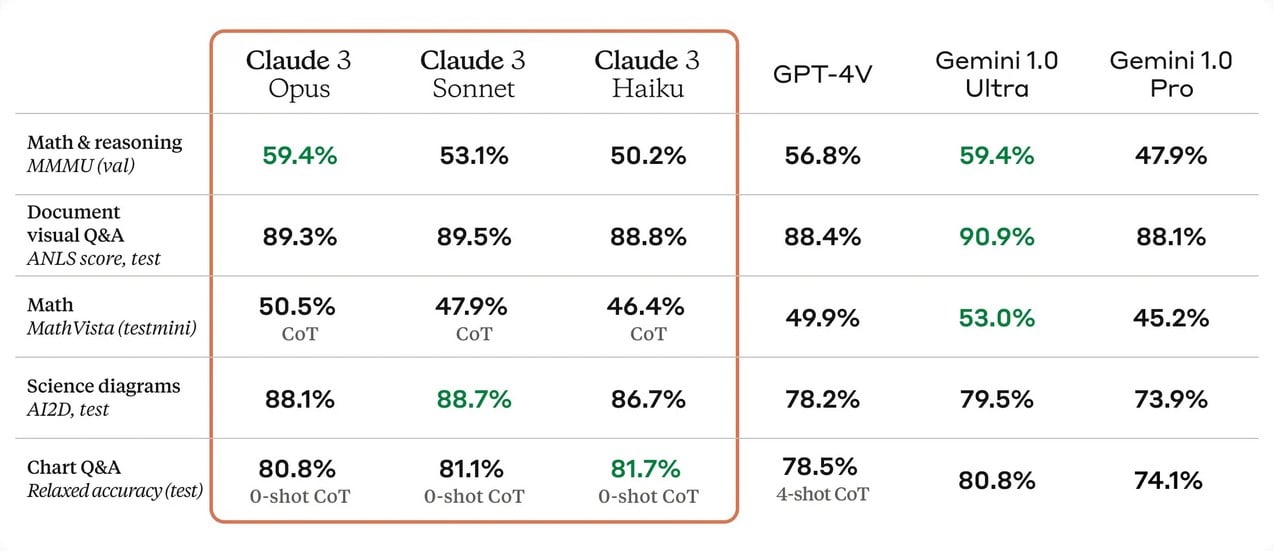
L’écart est encore plus large sur certains benchmarks de programmation, comme HumanEval. Opus a atteint un score de 84,9 %, contre seulement 67 % pour GPT-4 et 74,4 % pour Gemini 1.0 Ultra. Même si la différence est moins importante à ce niveau, il a aussi légèrement dépassé le modèle d’OpenAI sur plusieurs tests de connaissance générale et de raisonnement.
Claude 3 se distingue aussi par sa vitesse. À ce niveau, c’est surtout le petit poucet de la bande, Haiku, qui fait des merveilles. Selon Anthropic, ce dernier est capable d’extraire et de synthétiser des informations à partir d’articles scientifiques denses, pleins de jargon technique, en moins de trois secondes. Et ce même s’ils sont truffés d’images, de tableaux de données et de diagrammes, grâce à ses capacités multimodales avancées qui lui permettent de travailler sur n’importe quel type de support.
Une fenêtre de contexte énorme
Les trois variantes de Claude 3, et tout particulièrement Opus, se distinguent aussi sur un autre critère. Ces LLM sont des algorithmes prédictifs qui génèrent des séquences de mots en se basant sur un ensemble de tokens (des morceaux de texte de taille variable qui représente des mots, des bouts de mots ou des concepts). Cet ensemble est appelé fenêtre de contexte ; c’est un peu le champ de vision de l’algorithme. Plus cette fenêtre est longue, plus le modèle est performant lorsqu’il s’agit d’identifier des relations logiques entre les mots d’une séquence, et donc de proposer une réponse complète, cohérente et nuancée.
La longueur de la fenêtre de contexte est donc un paramètre crucial pour les performances de ces LLM. Jusqu’à présent, c’était ChatGPT qui faisait office de référence à ce niveau, avec sa fenêtre de contexte de 128 000 tokens — bien au-delà de Gemini 1.0, qui s’arrête à un maigre 8000 tokens. Mais la famille Claude 3 fait encore mieux. Les versions de bases des trois modèles commencent à un impressionnant 200 000 tokens, et Anthropic affirme même qu’ils pourront dépasser le million.
Des résultats à prendre avec des pincettes
Opus, Sonnet et Haiku affichent donc des performances assez bluffantes. Mais la prudence reste de mise au moment d’interpréter ces résultats. En effet, les benchmarks IA ne sont pas toujours parfaitement représentatifs des capacités réelles d’un modèle. Même si un LLM atteint des scores exceptionnels lors de ces examens, cela ne garantit pas qu’il fera aussi bien en conditions réelles, une fois confronté à des problèmes entièrement nouveaux.
De plus, il faut garder à l’esprit que les benchmarks IA sont notoirement exposés au phénomène de cherry picking, qui consiste à sélectionner soigneusement les résultats les plus impressionnants pour supporter une conclusion bien précise aux dépens de l’objectivité. Puisque ces LLM sont des produits commerciaux qui s’inscrivent dans un domaine où la compétition est extrêmement rude, il faut se méfier de ces chiffres.
Il est donc difficile de comparer précisément Claude 3 à ses concurrents directs pour déterminer objectivement lequel est le meilleur. Mais en définitive, les chiffres exacts sont assez anecdotiques. Ce qui est plus important, c’est la tendance qui se dégage de ses benchmarks, et Claude 3 semble bien se positionner comme un vrai rival à GPT-4. « C’est quand même énorme ; aucun autre modèle n’a battu GPT-4 comme ça sur un ensemble de benchmarks courants », reconnaît Simon Willison, un chercheur en IA interviewé par Ars Technica.
La guerre des LLM bat son plein
Ce qu’il faut retenir, c’est que la course aux LLM repart de plus belle. Désormais, tous les regards se tournent vers GPT-5, la prochaine itération du modèle d’OpenAI. Vu la trajectoire de la famille GPT, on peut s’attendre à une nouvelle explosion du nombre de paramètres, de la taille de la fenêtre de contexte, de la vitesse de traitement et des capacités multimodales.
Sa date de sortie n’a pas encore été annoncée officiellement, mais certains experts suggèrent qu’il pourrait débarquer en 2025 ; ce sera donc une bonne occasion de réaliser un nouvel état des lieux.
🟣 Pour ne manquer aucune news sur le Journal du Geek, suivez-nous sur Google et sur notre canal WhatsApp. Et si vous nous adorez, on a une newsletter tous les matins.