

Une équipe de chercheurs issue de l’université de Hong Kong et de l’Académie des Sciences chinoise a mis au point DeepFaceDrawing,une approche permettant de reconstituer des portraits photoréalistes à partir d’un simple gribouillis. Il en est sorti un nouvel outil basé sur l’intelligence artificielle, et dont le code sera bientôt disponible au grand public. Nous voyons ainsi arriver de nouveaux outils basés sur ces technologies, comme celui conçu par Nvidia qui permet de reconstituer des paysages photoréalistes à partir de croquis. Et le moins que l’on puisse dire, c’est que le résultat est assez bluffant ! Vous pouvez en juger par vous-même à l’aide de la vidéo qui accompagne le projet.
On y voit l’un des membres de l’équipe s’atteler à la création de plusieurs portraits en direct. Le tout fonctionne en temps réel, et on peut voir un portrait prendre forme au fur-et-à-mesure que le chercheur dessine. De la forme du visage aux cheveux en passant par le maquillage, la pilosité faciale et l’expression, le résultat est impressionnant de cohérence. A part quelques artefacts récurrents au niveau de la bouche et du bas des oreilles, toutes les “photos” produites semblent plausibles. Malheureusement, l’outil n’étant pas encore disponible au grand public, les chercheurs ont eu tout le loisir de sélectionner les exemples les plus impressionnants mais cela n’enlève rien à l’impression générale.
Comment ça marche ?
En règle générale, les systèmes fonctionnant avec une esquisse s’en servent comme d’une base, un canevas à partir duquel l’algorithme va tenter de reconstituer les données manquantes : couleur, éclairage… Sauf que cette approche a tendance à produire des résultats très distordus dès que l’on s’éloigne trop du type d’images de référence avec laquelle l’IA a été entraînée. Dans le papier de recherche correspondant, l’équipe du Pr. Shu-Yu Chen a changé d’approche : leur système apprend un ensemble d’esquisses de visages créés à partir de vraies esquisses de portraits, et sélectionne point par point celui qui représente la meilleure approximation du dessin qu’on lui fournit. L’esquisse constitue donc une contrainte “douce”, qui permet d’après les auteurs de “respecter fidèlement les intentions de l’utilisateur dans les traits qu’il trace”.
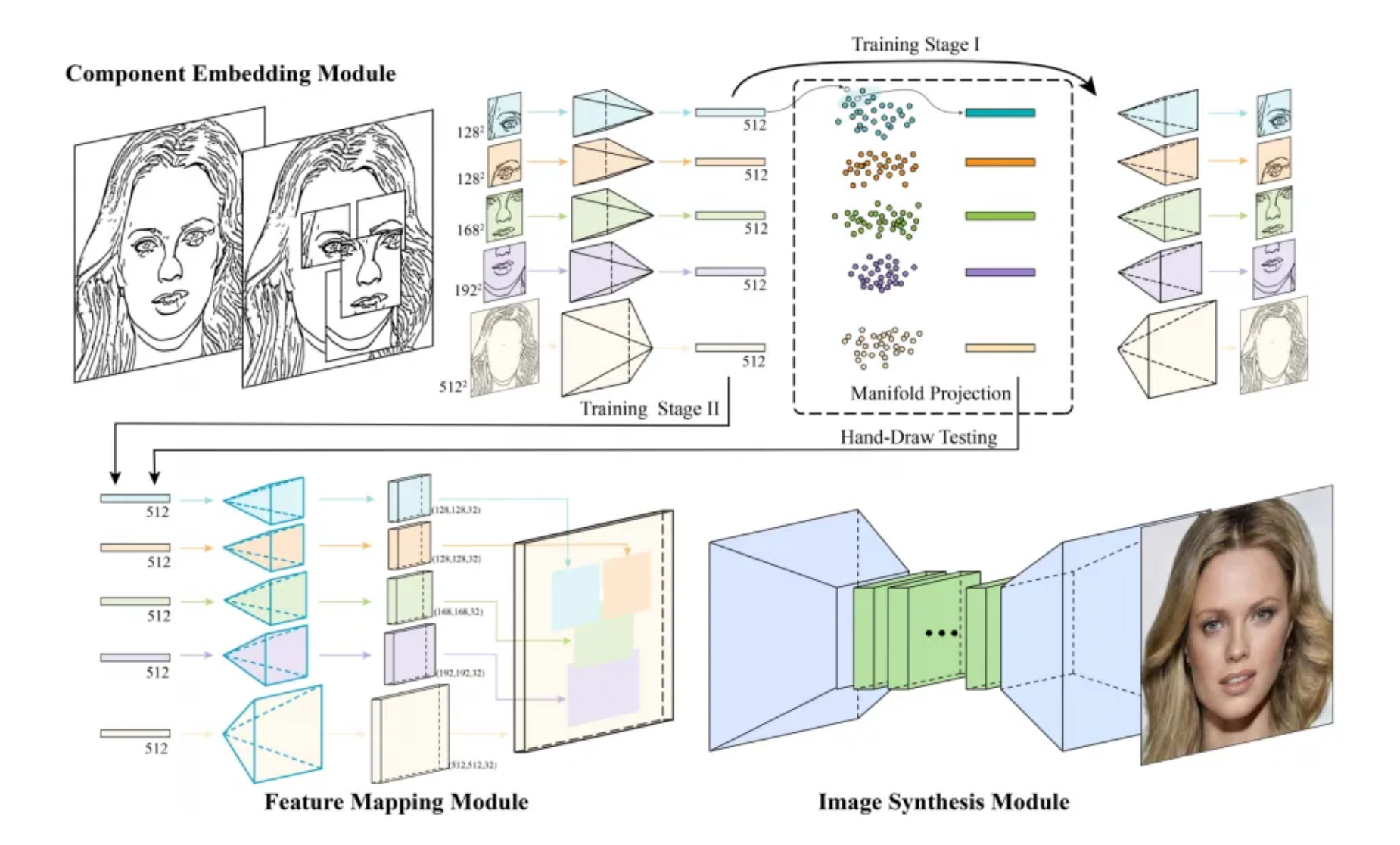
Le système est subdivisé en trois “modules” différents, ayant chacun leur fonction propre. Le premier est chargé d’apprendre à décrire et reconstituer les principaux repères du visage que sont par exemple les yeux, le nez, la bouche ou la forme globale du visage. Le second et le troisième fonctionnent ensemble pour reconstituer un visage entier, en assemblant des parties de visage à partir des informations générées par le premier module. Le tout permet de produire une image d’une résolution de 512×512 pixels, une assez bonne résolution par rapport à ce dont ce type d’outil est habituellement capable.
Le début de la fin de l’ “uncanny valley” ?
Ce n’est pas une surprise de voir ces systèmes basés sur l’IA devenir de plus en plus performants, à mesure que les technique s’affinent et que le matériel s’améliore. Mais cette approche représente un pas en avant assez impressionnant, car générer des visages est quelque chose de particulièrement ardu. En effet, notre cerveau est conditionné pour reconnaître instantanément un visage humain et les caractéristiques qui le définissent. Mais il est surtout particulièrement doué pour reconnaître une foultitude de micro-détails, que l’on ne perçoit pas consciemment mais participent grandement à la reconnaissance : l’infime asymétrie que l’on retrouve dans tous les visages en est un bon exemple. Mais supprimez ces subtils marqueurs de notre humanité, et d’un coup, la supercherie devient absolument criante, sans qu’on puisse pointer du doigt une difformité évidente. On appelle ce phénomène la “uncanny valley” ou “vallée de l’étrange”, et c’est ce qui explique pourquoi un robot aux traits caricaturaux nous paraîtra plus familier qu’un visage presque réaliste.
Et là où l’approche développée par cette équipe de chercheurs mérite d’être distinguée, c’est que ce facteur “uncanny valley” a quasiment disparu ! Certes, il faudra attendre d’avoir le code à disposition pour savoir si cela fonctionne aussi bien dans tous les cas, mais il faut admettre que des exemples proposés ne ressemblent pas à la version CGI du monstre de Frankenstein. Non seulement le tout est cohérent, mais il fourmille même de petits détails comme la tension aux commissures des lèvres, conséquence directe de son entraînement avec des images produites par des humains.
On peut aisément imaginer des tas d’utilisations possibles pour un tel système. Il pourrait par exemple servir aux forces de l’ordre pour reconstituer un portrait robot, ou pour générer du concept art pour des jeux vidéos ou films, par exemple. Mais comme toujours avec ces technologies, on peut également imaginer un monde où ces systèmes seraient employés à des fins de fraude ou de contrefaçon… Quoi qu’il en soit, nous avons hâte d’ avoir accès au code pour jouer un peu avec ce système !
🟣 Pour ne manquer aucune news sur le Journal du Geek, suivez-nous sur Google et sur notre canal WhatsApp. Et si vous nous adorez, on a une newsletter tous les matins.










