
Depuis sa présentation, le modèle d’IA Mythos d’Anthropic fait les titres de la presse. En effet, celle-ci est tellement performante qu’elle peut égaler les experts en cybersécurité pour trouver des failles de sécurité sur les logiciels, comme les navigateurs, les systèmes d’exploitation, ou même les logiciels utilisés dans le monde de la finance. Pour le moment, ce modèle n’est proposé qu’à certaines organisations. Mais on a déjà une idée concrète de ses performances.
Par exemple, en utilisant cette IA, la fondation Mozilla a découvert et corrigé plus de 400 failles sur Firefox. Et METR, qui a développé une méthode pour évaluer les compétences des modèles d’intelligence artificielle, indique que Mythos est tellement performant qu’il sera obligé de mettre à jour cette méthode afin d’évaluer avec précision le niveau de cette intelligence artificielle.
Une IA trop puissante pour l’évaluation
Cette évaluation s’appuie sur la “durée” des tâches. En substance, METR évalue le temps nécessaire pour un expert humain pour réaliser une tâche (par exemple, quelques secondes pour répondre à une question, moins de 6 minutes pour vérifier une information sur le web, ou moins de 16 heures pour “réduire au maximum la taille d’un modèle linguistique”). Plus une IA est performante, plus la “durée” des tâches qu’elle peut accomplir avec 50 % ou 80 % de chances de réussite est longue.
Ayant obtenu un accès anticipé à Claude Mythos, METR a donc évalué cette IA en utilisant cette méthode. Et la seule chose qui est certaine, c’est que cette IA est capable d’accomplir des tâches qui prennent plus de 16 heures, avec 50 % de chances de réussite. Mais, ça s’arrête là. En effet, pour mesurer les compétences de Claude Mythos avec plus de précision, la méthode d’évaluation devrait avoir de nouvelles tâches encore plus compliquées. “Les mesures supérieures à 16 heures ne sont pas fiables avec notre suite de tâches actuelle”, lit-on sur le site de METR.
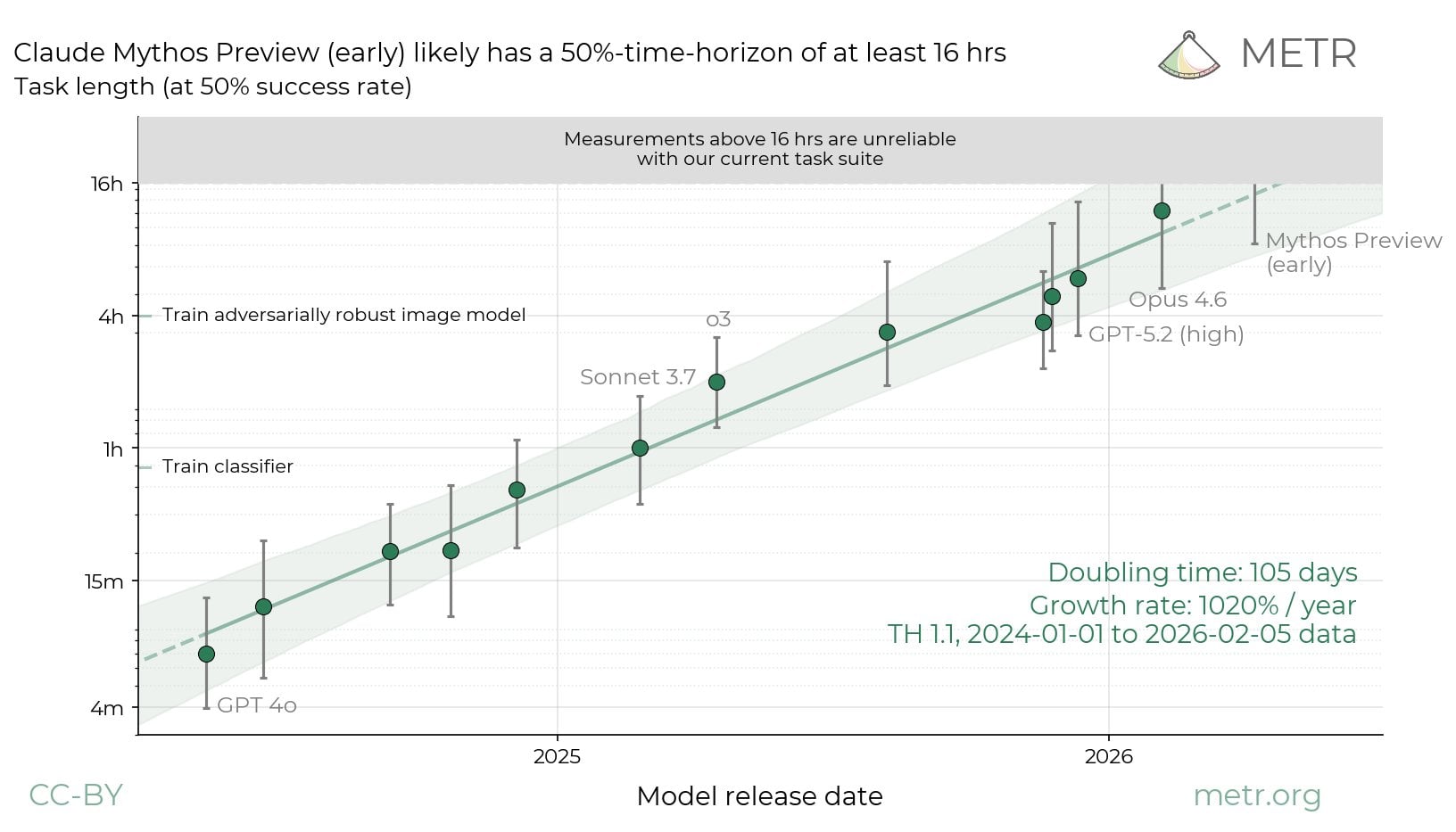
“Sur les 228 tâches de notre suite, seules 5 sont estimées à plus de 16 heures, ce qui rend les mesures dans cette fourchette instables et moins significatives que dans les fourchettes où la couverture des tâches est meilleure. Par conséquent, nous ne mettons pas en avant les estimations exactes pour les modèles dépassant 16 heures mesurés avec notre suite actuelle”, indique également METR sur X.
Of the 228 tasks in our suite, only 5 are estimated as 16+ hours long, making measurements at this range unstable and less meaningful than at ranges with better task coverage. Thus, we are not highlighting exact estimates for models above 16 hours measured with our current suite. pic.twitter.com/VJK9prGffE
— METR (@METR_Evals) May 8, 2026
🟣 Pour ne manquer aucune news sur le Journal du Geek, suivez-nous sur Google et sur notre canal WhatsApp. Et si vous nous adorez, on a une newsletter tous les matins.










